先来看一个问题:
Show how the value 0xabcdef12 would be arranged in memory of a little-endian and a big-endian machine. Assume the data is stored starting at address 0.
Little-Endian
Address | Value
0x0 | 0x12
0x1 | 0xef
0x2 | 0xcd
0x3 | 0xab
Big-Endian
Address | Value
0x0 | 0xab
0x1 | 0xcd
0x2 | 0xef
0x3 | 0x12
可以很明显地看出二者的区别
下面我们进行详细介绍
以下内容参考自:https://blog.csdn.net/gao_zhennan/article/details/124229168
一、字节序
endian 英 /ˈendɪən/ ,字节序
谈到字节序的问题,必然牵涉到两大CPU派系。那就是Motorola的PowerPC系列CPU和Intel的x86系列CPU。PowerPC系列采用big endian方式存储数据,而x86系列则采用little endian方式存储数据。那么究竟什么是big endian,什么又是little endian呢?
big endian是指低地址存放最高有效字节(MSB),而little endian则是低地址存放最低有效字节(LSB)。
用文字说明可能比较抽象,下面用图像加以说明。比如数字0x12345678在两种不同字节序CPU中的存储顺序如下所示:
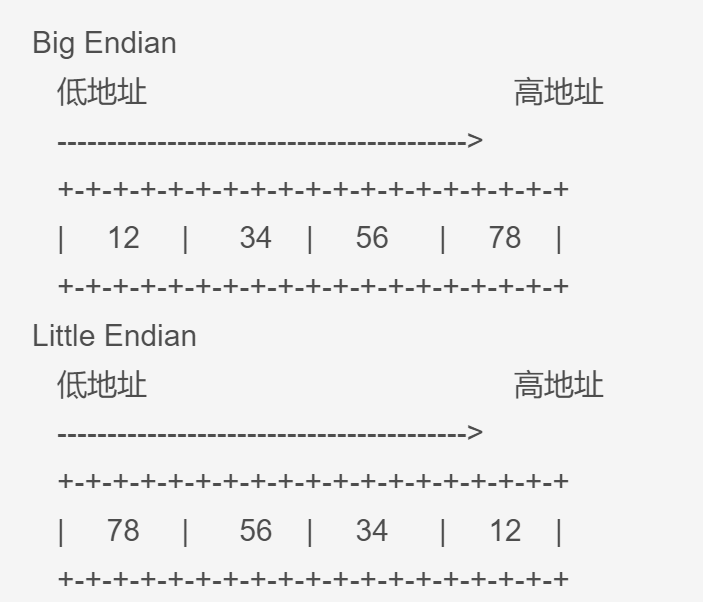
从上面两图可以看出,采用big endian方式存储数据是符合我们人类的思维习惯的。而little endian,!@#$%^&*,见鬼去吧 -_-|||
为什么要注意字节序的问题呢?你可能这么问。当然,如果你写的程序只在单机环境下面运行,并且不和别人的程序打交道,那么你完全可以忽略字节序的存在。但是,如果你的程序要跟别人的程序产生交互呢?在这里我想说说两种语言。C/C++语言编写的程序里数据存储顺序是跟编译平台所在的CPU相关的,而JAVA编写的程序则唯一采用big endian方式来存储数据。试想,如果你用C/C++语言在x86平台下编写的程序跟别人的JAVA程序互通时会产生什么结果?就拿上面的0x12345678来说,你的程序传递给别人的一个数据,将指向0x12345678的指针传给了JAVA程序,由于JAVA采取big endian方式存储数据,很自然的它会将你的数据翻译为0x78563412。什么?竟然变成另外一个数字了?是的,就是这种后果。因此,在你的C程序传给JAVA程序之前有必要进行字节序的转换工作。
无独有偶,所有网络协议也都是采用big endian的方式来传输数据的。所以有时我们也会把big endian方式称之为网络字节序。当两台采用不同字节序的主机通信时,在发送数据之前都必须经过字节序的转换成为网络字节序后再进行传输。ANSI C中提供了下面四个转换字节序的宏。 big endian:最高字节在地址最低位,最低字节在地址最高位,依次排列。 little endian:最低字节在最低位,最高字节在最高位,反序排列。 endian指的是当物理上的最小单元比逻辑上的最小单元小时,逻辑到物理的单元排布关系。咱们接触到的物理单元最小都是byte,在通信领域中,这里往往是bit,不过原理也是类似的。
一个例子:
如果我们将0x1234abcd写入到以0x0000开始的内存中,则结果为

目前应该little endian是主流,因为在数据类型转换的时候(尤其是指针转换)不用考虑地址问题。


